企业微信
web 自动化测试实战
课程目标
- 掌握 Web 自动化脚本编写能力
- 掌握 Web 自动化测试框架封装能力
- 掌握 Web 自动化测试框架优化能力
知识点总览
- 点击查看:web知识点梳理.xmind
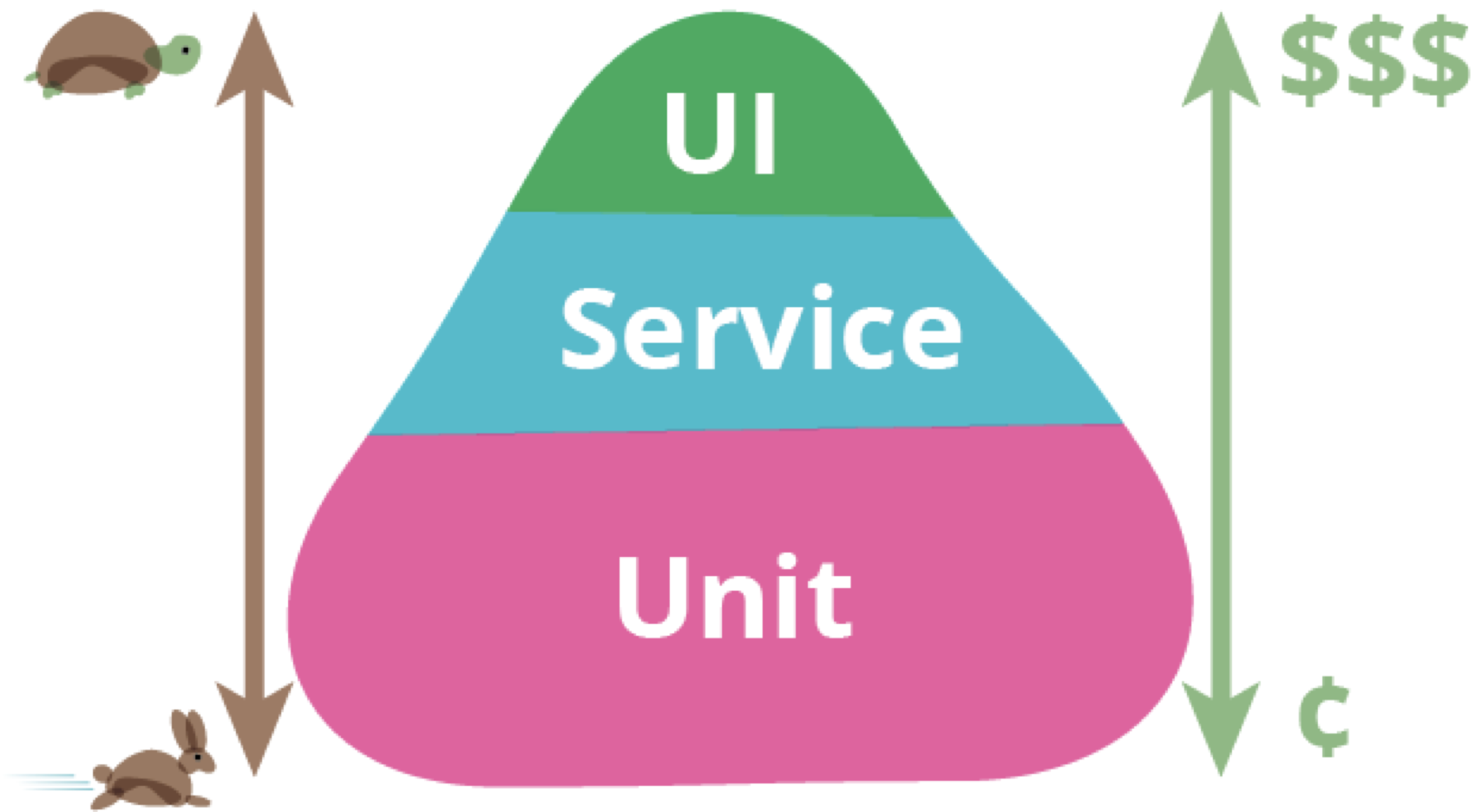
Web 自动化测试合适场景
- 业务流程不频繁改动
- UI 元素不频繁改动
- 需要频繁回归的场景
- 核心场景等
需求说明
- 企业微信是腾讯微信团队打造的企业通讯与办公工具,具有与微信一致的沟通体验,丰富的 OA 应用,和连接微信生态的能力,可帮助企业连接内部、连接生态伙伴、连接消费者。
- 完成企业微信的 Web 自动化测试
- 完成登录企业微信 Web 端自动化用例
- 完成添加成员自动化用例
- 完成删除成员自动化用例
- 输出测试报告
- 完成 Web 自动化测试框架搭建
- 在自动化测试框架中编写企业微信添加成员测试用例
- 优化测试框架
- 输出测试报告

实战思路

设计测试用例
| 测试模块 | 用例标题 | 前置条件 | 用例步骤 | 预期结果 | 实际结果 |
|---|---|---|---|---|---|
| 成员模块 | 添加成员 | 登录成功 | 1. 点击顶部栏【通讯录】按钮 2. 点击添加成员按钮 3. 输入成员信息点击保存 4. 验证成员列表页面 |
1.进入通讯录页面 2.进入添加成员界面 3. 成功添加学员 4. 添加成功的成员展示在成员列表里面 |
|
| 成员模块 | 添加成员,输入重复账号 | 登录成功 | 1. 点击顶部栏【通讯录】按钮 2. 点击添加成员按钮 3. 输入重复标识的成员信息点击保存 |
1.进入通讯录页面 2.进入添加成员界面 3. 添加学员失败提示账号已被占用 |
搭建 Web 自动化测试环境
- Selenium 4.x 可以自动下载对应版本的 driver
- 如果下载不成功,可以手动配置 driver
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# 手动配置 driver
service = Service(executable_path="./chrome_driver/chromedriver")
driver = webdriver.Chrome(service=service)
# 自动配置 driver
# driver = webdriver.Chrome()
登录企业微信 Web 端
使用 Cookie 复用方式登录
# 保存 cookie
# 1. 访问企业微信主页/登录页面
self.driver.get(url)
# 2. 等待30s,人工扫码操作
time.sleep(30)
# 3. 等成功登陆之后,再去获取cookie信息
cookie = self.driver.get_cookies()
print(cookie)
# 将 cookie 写入文件
with open("cookie.yaml", "w") as f:
yaml.safe_dump(cookie, f)
# 使用 cookie 登录
# 从文件中获取 cookie 信息登陆
with open("cookie.yaml", "r", encoding="utf-8") as f:
cookies = yaml.safe_load(f)
print(f"读取出来的cookie:{cookies}")
for cookie in cookies:
try:
# 添加 cookie
self.driver.add_cookie(cookie)
except Exception as e:
print(e)
time.sleep(3)
通讯录添加成员
- 步骤:
- 登录
- 进入首页
- 点击【通讯录】按钮
- 点击【添加成员】按钮
- 填写添加成员信息
- 点击【保存】按钮
- 验证 ==> 断言
- 测试数据准备:Faker
- 获取国内数据的方法
- 安装:
pip install Faker
# test_wework_contact.py
class TestWeworkContact:
def setup_class(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(15)
self.driver.get("https://work.weixin.qq.com/wework_admin/frame#index")
self.driver.maximize_window()
self.fake = Faker("zh_CN")
time.sleep(1)
# 从文件中获取 cookie 信息登陆
with open("cookie.yaml", "r", encoding="utf-8") as f:
cookies = yaml.safe_load(f)
print(f"读取出来的cookie:{cookies}")
for cookie in cookies:
try:
# 添加 cookie
self.driver.add_cookie(cookie)
except Exception as e:
print(e)
time.sleep(3)
self.driver.get("https://work.weixin.qq.com/wework_admin/frame#index")
def teardown_class(self):
self.driver.quit()
def test_add_member(self):
'''
添加成员
:return:
'''
# 数据准备
# 姓名
mname = self.fake.name()
# 账号
mid = self.fake.uuid4()
# 手机号
phone_num = self.fake.phone_number()
# 点击通讯录按钮
self.driver.find_element(By.ID, "menu_contacts").click()
# 进入通讯录页面
# 显式等待成员列表加载完毕
WebDriverWait(self.driver, 10).until(
expected_conditions.visibility_of_element_located(
(By.ID, "member_list")
)
)
# 点击添加成员按钮
self.driver.find_element(
By.CSS_SELECTOR,
".ww_operationBar .js_add_member"
).click()
# 显式等待输入姓名出现
WebDriverWait(self.driver, 10).until(
expected_conditions.visibility_of_element_located(
(By.ID, "username")
)
)
# 输入姓名
self.driver.find_element(
By.ID, "username"
).send_keys(mname)
# 输入账号
self.driver.find_element(
By.ID, "memberAdd_acctid"
).send_keys(mid)
# 输入手机号
self.driver.find_element(
By.ID, "memberAdd_phone"
).send_keys(phone_num)
# 点击保存按钮
self.driver.find_element(
By.CSS_SELECTOR,
".qui_btn.ww_btn.js_btn_save"
).click()
# 获取保存结果提示信息
tips = WebDriverWait(self.driver, 10).until(
expected_conditions.element_to_be_clickable(
(By.ID, "js_tips")
)
)
# 根据提示信息断言
assert tips.text == "保存成功"
# 等待成员列表加载完毕
WebDriverWait(self.driver, 10).until(
expected_conditions.element_to_be_clickable(
(By.ID, "member_list")
)
)
# 获取成员列表信息
# 定位 .member_colRight_memberTable_td 同一级兄弟元素中的第二个
names = self.driver.find_elements(
By.CSS_SELECTOR,
".member_colRight_memberTable_td:nth-child(2)"
)
# 使用列表推导式获取成员姓名,放入列表
name_list = [n.text for n in names]
# 断言新添加成员姓名在列表中
assert mname in name_list
使用 PO 模式封装测试框架
- 线性脚本中存在的问题
- 无法适应 UI 频繁变化
- 无法清晰表达业务用例场景
- 大量的样板代码 driver/find/click
- 解决方案
- 领域模型适配:封装业务实现,实现业务管理
- 提高效率:降低用例维护成本,提高执行效率
- 增强功能:解决已有框架不满足的情况
PO 模式建模原则
-
属性意义
- 不要暴露页面内部的元素给外部。
- 不需要建模 UI 内的所有元素。
- 方法意义
- 用公共方法代表 UI 所提供的功能。
- 方法应该返回其他的 PageObject 或者返回用于断言的数据。
- 同样的行为不同的结果可以建模为不同的方法。
- 不要在方法内加断言。
企业微信 Web 端 PO 建模
以下为添加成员功能的原型图。

- 根据原型图可以梳理添加成员的业务逻辑如下:
- 方块代表一个类
- 每条线代表这个页面提供的方法
- 箭头的始端为开始页面
- 箭头的末端为跳转页面或需要断言的数据

框架梳理

项目结构
项目的整个结构如下图所示。
Hogwarts $ tree
.
├── __init__.py
├── base
│ ├── __init__.py
│ └── base_page.py
├── tests
│ ├── __init__.py
│ └── test_xxx.py
├── log
│ ├── test.txt
├── datas
│ └── xxx.yaml
├── page
│ ├── __init__.py
│ ├── main_page.py
│ ├── xxx_page.py
│ └── xxx_page.py
└── utils
├── __init__.py
└── log_utils.py
构造页面相关类和方法 - base
# base/base_page.py
class BasePage:
def __init__(self):
self.driver = None
构造页面相关类和方法 - page
# page/main_page.py
class MainPage(BasePage):
def login(self):
'''
登录,进入首页
:return:
'''
return self
def goto_contact_page(self):
'''
点击通讯录按钮,跳转通讯录按钮
:return:
'''
return ContactPage()
# page/contact_page.py
class ContactPage(BasePage):
def goto_add_member_page(self):
'''
点击添加成员按钮,进入添加成员界面
:return:
'''
from test_frame.page.add_member_page import AddMemberPage
return AddMemberPage()
def get_contact_member_list(self):
'''
获取通讯录用户列表
:return:
'''
return ["feier"]
# page/add_member_page.py
class AddMemberPage(BasePage):
def input_member_info(self):
'''
输入成员信息,点击保存按钮,跳转通讯录页面
:return:
'''
return ContactPage()
构造页面相关类和方法 - tests
# tests/test_add_member.py
class TestAddMember:
def setup_class(self):
self.main = MainPage()
def test_add_member_success(self):
name_list = self.main.login().\
goto_contact_page().\
goto_add_member_page().\
input_member_info().\
get_contact_member_list()
assert "feier" in name_list
填充测试框架
# 代码详见仓库
优化测试框架
- 基类中封装常用方法:base_page.py
- 定义好之后,其他 page 中调用基类中封装好的方法即可。
class BasePage:
def __init__(self, driver: WebDriver=None):
if driver == None:
service = Service(executable_path="../../chrome_driver/chromedriver")
self.driver = webdriver.Chrome(service=service)
# self.driver = webdriver.Chrome()
else:
self.driver = driver
self.driver.implicitly_wait(15)
self.driver.maximize_window()
def close_browser(self):
'''
关闭浏览器
:return:
'''
self.driver.quit()
def open_url(self, url):
'''
打开网页
:param url: 要打开页面的 url
:return:
'''
self.driver.get(url)
def find_ele(self, by, value):
'''
查找单个元素
:param by: 元素定位方式
:param value: 元素定位表达式
:return: 找到的元素对象
'''
ele = self.driver.find_element(by, value)
return ele
def find_eles(self, by, value):
'''
查找多个元素
:param by: 元素定位方式
:param value: 元素定位表达式
:return: 元素列表
'''
eles = self.driver.find_elements(by, value)
return eles
def find_and_get_text(self, by, value):
'''
获取单个元素的文本属性
:param by: 元素定位方式
:param value: 元素定位表达式
:return: 文本内容
'''
text_value = self.find_ele(by, value).text
return text_value
def click_ele(self, by, value):
'''
查找单个元素并点击
:param by: 元素定位方式
:param value: 元素定位表达式
'''
self.find_ele(by, value).click()
def ele_sendkeys(self, by, value, text):
'''
单个元素输入内容
:param by: 元素定位方式
:param value: 元素定位表达式
:param text: 要输入的内容字符串
'''
# 清除内容
self.find_ele(by, value).clear()
# 输入内容
self.find_ele(by, value).send_keys(text)
def wait_ele_located(self, by, value, timetout=10):
'''
显式等待元素可以被定位
:param by: 元素定位方式
:param value: 元素定位表达式
:param timetout: 等待时间
:return: 定位到的元素对象
'''
ele = WebDriverWait(self.driver, timetout).until(
expected_conditions.visibility_of_element_located((by, value))
)
return ele
def wait_ele_click(self, by, value, timeout=10):
'''
显式等待元素可以被点击
:param by: 元素定位方式
:param value: 元素定位表达式
:param timeout: 等待时间
'''
ele = WebDriverWait(self.driver, timeout).until(
expected_conditions.element_to_be_clickable((by, value))
)
return ele
def login_by_cookie(self):
'''
通过 cookie 登录
:return:
'''
# 从文件中获取 cookie 信息登陆
with open("../datas/cookie.yaml", "r", encoding="utf-8") as f:
cookies = yaml.safe_load(f)
print(f"读取出来的cookie:{cookies}")
for cookie in cookies:
# 添加 cookie
self.driver.add_cookie(cookie)
# 刷新页面
self.driver.refresh()
添加日志
utils 包下创建单独的日志文件。
import logging
import os
from logging.handlers import RotatingFileHandler
# 绑定绑定句柄到logger对象
logger = logging.getLogger(__name__)
# 获取当前工具文件所在的路径
root_path = os.path.dirname(os.path.abspath(__file__))
# 拼接当前要输出日志的路径
log_dir_path = os.sep.join([root_path, '..', f'/logs'])
if not os.path.isdir(log_dir_path):
os.mkdir(log_dir_path)
# 创建日志记录器,指明日志保存路径,每个日志的大小,保存日志的上限
file_log_handler = RotatingFileHandler(os.sep.join([log_dir_path, 'log.txt']), maxBytes=1024 * 1024, backupCount=10 , encoding="utf-8")
# 设置日志的格式
date_string = '%Y-%m-%d %H:%M:%S'
formatter = logging.Formatter(
'[%(asctime)s] [%(levelname)s] [%(filename)s]/[line: %(lineno)d]/[%(funcName)s] %(message)s ', date_string)
# 日志输出到控制台的句柄
stream_handler = logging.StreamHandler()
# 将日志记录器指定日志的格式
file_log_handler.setFormatter(formatter)
stream_handler.setFormatter(formatter)
# 为全局的日志工具对象添加日志记录器
# 绑定绑定句柄到logger对象
logger.addHandler(stream_handler)
logger.addHandler(file_log_handler)
# 设置日志输出级别
logger.setLevel(level=logging.INFO)
其他页面导入 logger 即可定义不同级别的日志。
class BasePage:
...
def find_ele(self, by, value):
'''
查找单个元素
:param by: 元素定位方式
:param value: 元素定位表达式
:return: 找到的元素对象
'''
logger.info(f"定位单个元素,定位方式为 {by}, 定位表达式为 {value}")
报错截图并保存 PageSource
- 在基类中添加截图和保存 page_source 的方法。
- 在查找元素的方法中添加异常处理,当找不到元素时,完成截图和页面源码保存。
class BasePage:
def find_ele(self, by, value):
'''
查找单个元素
:param by: 元素定位方式
:param value: 元素定位表达式
:return: 找到的元素对象
'''
logger.info(f"定位单个元素,定位方式为 {by}, 定位表达式为 {value}")
try:
ele = self.driver.find_element(by, value)
except Exception as e:
ele = None
logger.info(f"单个元素没有找到 {e}")
# 截图
self.screen_image()
# 保存日志
self.save_page_source()
return ele
def get_path(self, path_name):
'''
获取绝对路径
:param path_name: 目录名称
:return: 目录绝对路径
'''
# 获取当前工具文件所在的路径
root_path = os.path.dirname(os.path.abspath(__file__))
# 拼接当前要输出日志的路径
dir_path = os.sep.join([root_path, '..', f'/{path_name}'])
return dir_path
def screen_image(self):
'''
截图
:return: 图片保存路径
'''
# 截图命名
now_time = time.strftime('%Y_%m_%d_%H_%M_%S')
image_name = f"{now_time}.png"
# 拼接截图保存路径
# windows f"{self.get_path('image')}\\{image_name}"
image_path = f"{self.get_path('image')}/{image_name}"
logger.info(f"截图保存路径为 {image_path}")
# 截图
self.driver.save_screenshot(image_path)
return image_path
def save_page_source(self):
'''
保存页面源码
:return: 页面源码保存路径
'''
# 文件命名
now_time = time.strftime('%Y_%m_%d_%H_%M_%S')
pagesource_name = f"{now_time}_pagesource.html"
# 拼接文件保存路径
# windows f"{self.get_path('pagesource')}\\{pagesource_name}"
pagesource_path = f"{self.get_path('pagesource')}/{pagesource_name}"
logger.info(f"页面源码文件保存路径为 {pagesource_path}")
# 保存 page source
with open(pagesource_path, "w", encoding="utf-8") as f:
f.write(self.driver.page_source)
return pagesource_path
生成测试报告
- 添加 allure 步骤描述
- 在页面中每个方法上方添加步骤描述
# main_page.py
class MainPage(BasePage):
@allure.step("登录企业微信 web 端,进入首页")
def login(self):
'''
登录,进入首页
:return:
'''
# contact_page.py
class ContactPage(BasePage):
@allure.step("点击添加成员按钮,进入添加成员界面")
def goto_add_member_page(self):
'''
点击添加成员按钮,进入添加成员界面
:return:
'''
@allure.step("获取通讯录用户列表")
def get_contact_member_list(self):
'''
获取通讯录用户列表
:return:
'''
# add_member_page.py
class AddMemberPage(BasePage):
@allure.step("输入成员信息,点击保存按钮,跳转通讯录页面")
def input_member_info(self, mname, mid, phone_num):
'''
输入成员信息,点击保存按钮,跳转通讯录页面
:return:
'''
allure 报告中添加文件
- base_page.py 文件中,在截图和保存page_source 方法中添加文件到 allure。
class BasePage:
...
def get_path(self, path_name):
'''
获取绝对路径
:param path_name: 目录名称
:return: 目录绝对路径
'''
# 获取当前工具文件所在的路径
root_path = os.path.dirname(os.path.abspath(__file__))
# 拼接当前要输出日志的路径
dir_path = os.sep.join([root_path, '..', f'/{path_name}'])
return dir_path
def screen_image(self):
'''
截图
:return: 图片保存路径
'''
# 截图命名
now_time = time.strftime('%Y_%m_%d_%H_%M_%S')
image_name = f"{now_time}.png"
# 拼接截图保存路径
# windows f"{self.get_path('image')}\\{image_name}"
image_path = f"{self.get_path('image')}/{image_name}"
logger.info(f"截图保存路径为 {image_path}")
# 截图
self.driver.save_screenshot(image_path)
# 添加截图到 allure
allure.attach.file(image_path, name="查找元素异常截图",
attachment_type=allure.attachment_type.PNG)
return image_path
def save_page_source(self):
'''
保存页面源码
:return: 页面源码保存路径
'''
# 文件命名
now_time = time.strftime('%Y_%m_%d_%H_%M_%S')
pagesource_name = f"{now_time}_pagesource.html"
# 拼接文件保存路径
# windows f"{self.get_path('pagesource')}\\{pagesource_name}"
pagesource_path = f"{self.get_path('pagesource')}/{pagesource_name}"
logger.info(f"页面源码文件保存路径为 {pagesource_path}")
# 保存 page source
with open(pagesource_path, "w", encoding="utf-8") as f:
f.write(self.driver.page_source)
# pagesource 添加到 allure 报告
allure.attach.file(pagesource_path, name="查找元素异常的页面源码",
attachment_type=allure.attachment_type.TEXT)
return pagesource_path
测试用例中添加 allure 描述
@allure.feature("企业微信 Web 端")
class TestAddMember:
@allure.story("添加成员")
@allure.title("添加成员-冒烟用例")
def test_add_member(self):
'''
添加成员冒烟用例
:return:
'''
执行命令生成报告
pytest -v --alluredir=./results --clean-alluredir
allure serve ./results
allure generate --clean alluredir results -o results/html
总结
- Selenium 环境搭建
- Selenium 自动化脚本编写
- PO 模式封装 Web 自动化测试框架
- 框架优化
- 报错保存日志
- 报错截图并保存 PageSource
- 添加测试报告描述